April 2, 2026
Ralph-NG: Your AI Shouldn't Grade Its Own Homework
Claude writes the code. Codex reviews it blind. If they disagree, they argue. If they're stuck, a human steps in. Here's how I built it.
I already had half the answer
When I shipped Crossfire a few weeks ago, I ended the blogpost with a line I’d been thinking about for a while: “I suspect this won’t stay a spec-only tool for long.”
That wasn’t a teaser. It was me admitting out loud that I’d already started building the next piece.
Crossfire proved something I’d suspected but couldn’t quantify: adversarial debate between two models produces dramatically better output than either model alone. The sycophancy problem is real — a single model reviewing its own work is like proofreading your own essay. You read what you meant to write, not what you actually wrote. But when a second model with different training data examines the same artifact and is explicitly told to find problems? It finds problems. Real ones.
Nielsen’s adversarial-review research backed this up with hard numbers. Single-model code review: 53% of bugs caught. Two models in structured debate: 80%. And all the hard system-level bugs. Not because model B was smarter. Because someone told it to look for what model A missed.
So Crossfire handled the spec side. Two models argue until they converge on a plan that’s actually buildable. 19,000 characters of implementation plan with file paths, TDD tasks, and acceptance criteria. The specs were good. Really good.
But specs don’t ship.
I’d been running autonomous coding loops for a while at that point — first with the original ralph project, then with my own awesome-ai-workflow which extended ralph with tiered complexity, planning, reflection, and multi-CLI support. Those tools proved that a bash script piping prompts into an AI CLI can absolutely produce committed, tested code with zero human involvement. But they shared the same fundamental blind spot: same model writes the code, same model reviews it, same systematic biases carry through unchallenged.
And there I was, sitting on a working debate engine from Crossfire that already solved adversarial cross-model review for specs. The transport normalization, the anti-sycophancy protocol, the Codex JSONL parsing — all of it battle-tested. The question wasn’t whether to apply that pattern to code execution. It was how fast I could port those concepts into a Python orchestrator and wire them into a proper task lifecycle.
Stealing from myself (and Jesse Vincent)
One of the earliest design decisions in ralph-ng was explicit: reuse Crossfire and Superpowers patterns, not their runtimes.
From Crossfire, I ported the conceptual architecture: the event normalization that turns two completely different CLI output formats into a common stream, the Codex JSONL parsing, the Claude subprocess handling, and the anti-sycophancy prompting protocol (adapted from debate mode to review mode).
From Jesse Vincent’s Superpowers, I ported the review philosophy: the anti-trust reviewer framing, the structured quality checklist pattern, the “evidence-before-claims” gate. Superpowers solved the hardest review-prompting problem — how to make an AI reviewer actually distrust the implementer’s output. I wasn’t about to reinvent that.
But I didn’t want Crossfire’s Fastify daemon, React web UI, or session browser. And I didn’t want Superpowers’ skill activation system or hook infrastructure. I wanted a Python CLI that reads a YAML plan and executes it task by task with adversarial review baked into every step.
So I cherry-picked the hard-won patterns and left the runtime machinery behind.
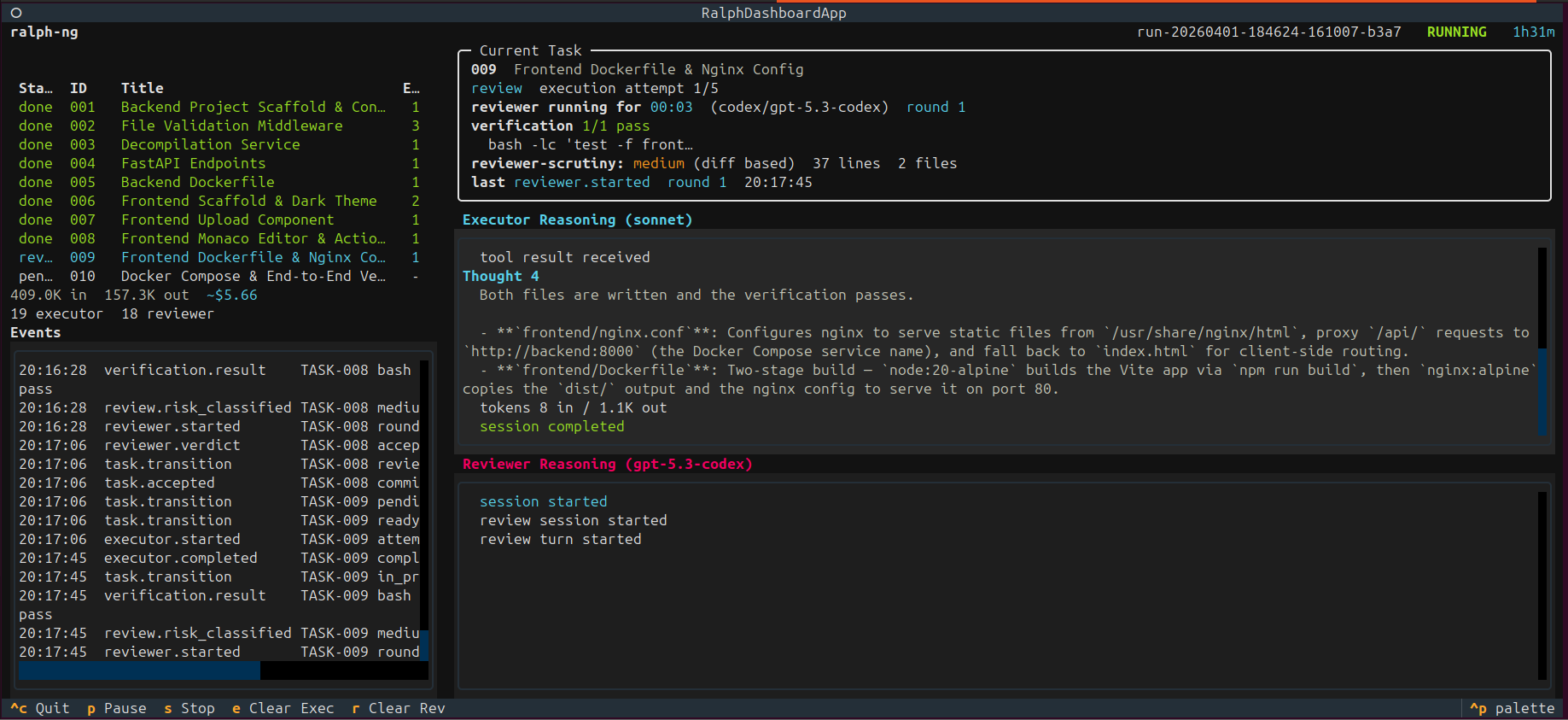
Ralph-NG: what it actually is
8,600 lines of Python. 433 tests. One very specific opinion about how AI should write code: not alone.
You give it a ralph-plan.yaml — tasks, dependencies, acceptance criteria, verification commands — and it executes that plan task by task. But here’s the thing that makes it different from every other AI coding loop I’ve seen: the model that writes the code is not the model that reviews it.
The loop:
- Scheduler picks the next ready task (dependencies satisfied)
- Executor (Claude) implements it — full Claude Code capabilities, file access, shell, git, the works
- Verification commands run locally — pytest, linting, whatever you configured
- Reviewer (Codex) examines the diff blind
- Accept → commit, next task. Reject → executor gets specific findings, repairs, responds with evidence. Stuck → escalate to a human
Step 4 is where it gets interesting. The reviewer works from a ReviewBundle: the task contract, the git diff, snippets of the changed files, and the verification results. That’s it. No executor reasoning. No chain-of-thought. No “here’s why I made this choice.” The reviewer forms its own opinion from the evidence alone.
This was a deliberate design choice, not an afterthought. The v0.2 spec (Decision 5) puts it plainly: “The reviewer should not initially see the executor’s rationale. Independent review comes before adversarial challenge.” Research shows LLMs exhibit systematic anchoring when exposed to prior reasoning. If the reviewer sees how the executor was thinking, it anchors on that framing. Independence first. Always.
And when the reviewer does push back, the response protocol matters too. Decision 6 in the spec: “Repair-first, then explain — not argue-first.” After Codex rejects, Claude has to fix the code first, then explain what changed and why the finding is addressed (or was already fine). This is the opposite of Crossfire’s debate model, where models argue over prose. A new diff is machine-checkable. A prose rebuttal is not. Pure rebuttal creates an incentive for the model to argue its way out of work.
If they can’t resolve it within bounded rounds, it escalates to you.
CLI-first (and yes, I know what you’re thinking)
“But Jean, why are you shelling out to CLI tools instead of calling the APIs?”
This was the first core design decision — literally Decision 1 in the design doc — and I get asked about it constantly.
Money. If you’re paying for Claude Code and Codex subscriptions (and let’s be real, most of us building with these tools are), those are flat-rate. API calls are per-token on top of that. For a system that makes 20+ LLM calls per run with big prompts, the token costs add up fast. Ralph-NG runs on subscriptions you’ve already got.
Capability. Through the CLI, Claude is Claude Code — it reads your codebase, runs tests, fixes its own mistakes, hits MCP servers. Through the API, it’s a language model that returns text. There’s a massive capability gap. The existing multi-agent frameworks (CrewAI, AutoGen, Swarm) all assume programmatic API access with structured function calling. They treat the model as a stateless function: input → structured output → parse → loop. Ralph-NG treats each invocation as a fully autonomous coding agent that happens to communicate through an orchestrator. We coordinate at the task level, not the token level.
The trade-off is real: you lose structured tool_calls, fine-grained streaming control, and have to parse whatever the CLI decides to give you.
Which brings us to the maiden voyage.
13 runs, 83 invocations, and a lot of humility
I ran ralph-ng’s first real test against a timezone conversion project. Over two days (March 20-21), I kicked off 13 runs totaling 83 provider invocations. The results were… educational.
Three of those 13 runs failed because Codex’s reasoning mode produced multiple JSON objects concatenated together. The reviewer prompt said “respond with a JSON object matching the ReviewFindings schema” but didn’t say “emit exactly one JSON object.” Codex helpfully produced a placeholder JSON, then 3-5 iteratively refined JSON objects, one after another, no delimiters. The multi-object fallback parser tried to pick the right one. Pydantic validation rejected them all. Run 991f, run 84a1, run 3198 — all the same pattern.
The fix was literally a one-line prompt change. “Emit exactly one JSON object.” But finding it required running real models on real tasks and watching the actual output instead of assuming “respond with a JSON object” was unambiguous. It wasn’t.
Four runs got stuck in running status long after the controller process was dead. Run 958d: status running, last event reviewer.started, 33 minutes stale with nothing happening. Run e57b and 1fde: both in_progress, both 50+ minutes stale. The heartbeat was emitted by the display thread, but the orchestrator thread blocks on synchronous provider calls. If the process dies mid-call, the heartbeat stops but nobody notices. The run just… sits there.
One run (ea8d) had the executor exit with status 143. That’s 128 + 15, a.k.a. SIGTERM. Was it a provider crash? An operator ctrl-c? The system couldn’t tell — both produce the same exit code. It logged “Claude exited with status 143” and stopped. Not helpful.
Another run (eeeb) had Claude crash in 0.72 seconds. Less than a second. No diagnostic info captured, just “Claude exited with status 1.” The system treated it identically to a 10-minute timeout. Those are not the same failure and they need different recovery strategies.
And then there was 3943. TASK-004 consumed four attempts because the verification commands used rg (ripgrep), which wasn’t installed. The ratchet system correctly rejected rg commands (return code 127), but the executor kept generating rg-based commands, and the reviewer kept suggesting “install rg or use a portable equivalent.” Eventually on attempt 4 the executor figured out grep -nE works fine. Four attempts for something a prompt instruction (“prefer portable commands like grep -nE over rg”) would have prevented.
And my personal favorite: run 1a62. The executor spent 372 seconds building a Vite + React + Shadcn scaffold. Reviewer correctly identified that class-variance-authority, clsx, and tailwind-merge were imported by the generated Shadcn components but never declared in package.json. Escalated to blocked_human at confidence 0.93. The reviewer was right. The executor generated code that imported packages it never installed.
Every one of those failures became a specific fix. The reliability hardening spec I wrote afterward cites actual run IDs, actual failure evidence, actual code paths. Not theoretical failure modes. Real ones, with receipts.
What broke and what I built to fix it
The multi-JSON problem → prompt hardening
The fix was cheap: tell the model to emit one object. But the lesson was expensive: Codex’s reasoning mode doesn’t just produce one answer. It produces intermediate refinement passes, each shaped like valid JSON. Your parser better handle that, or your prompt better prevent it. I went with the prompt route because parsing “which of these five JSON objects is the real one” is a game I didn’t wanna play.
Orphaned runs → heartbeat from both threads + stale controller adoption
The orchestrator blocks on I/O during provider calls. Moving heartbeats to the orchestrator alone wouldn’t work — it’s stuck waiting for stdout. The fix: heartbeat from both the display thread (on a timer) and from within the streaming subprocess reader (on each line of output). Plus stale controller detection: if the heartbeat is older than 30 seconds or the PID is dead, a new ralph resume automatically adopts the orphaned run.
Ambiguous exit codes → 15-class failure classification
“Exit code 1” is not a diagnosis. Ralph-NG now classifies every failure using exit code, duration, stderr content, and timeout flags:
| Failure class | How it’s detected | Recovery |
|---|---|---|
| Provider timeout | timed_out flag | Retry once |
| Provider crash | exit_code=1, duration < 2s | Retry up to 2x |
| Rate limit | ”rate limit” in stderr | Exponential backoff, 3 retries |
| Missing binary | exit_code=127 | Self-healing diagnosis |
| Missing project dep | Package not in manifest | Auto-install |
| Signal kill (SIGTERM) | exit_code=143 | Classify as operator vs crash |
| Verification failure | Test exit code != 0 | Bounded repair loop |
The sub-2-second crash class was the one that surprised me. Claude CLI can fail to initialize for a dozen reasons (bad config, auth expired, rate limit, malformed arguments) and they all look like “exit code 1” if you don’t check the duration. A 0.72-second “failure” is not the same as a 10-minute timeout, and the recovery strategy should be different.
Missing dependencies → prompt instructions + self-healing
The rg problem and the Shadcn dependency problem were two faces of the same gap: the executor prompt didn’t say anything about dependency management or portable commands. Now it does. “Check the project manifest before importing new packages. Prefer portable commands (grep -nE, find) over tools that may not be installed (rg, fd).”
And for when that’s not enough, the self-healing engine. On recoverable failures, ralph-ng spawns a separate diagnosis session that analyzes the evidence, classifies the root cause, and recommends bounded auto-fix actions. The fix scope is locked down tight though — npm install? Fine. pip install? Fine. sudo apt install? Absolutely not. rm -rf? Over my dead body. I’m a security person. I think about worst-case scenarios with auto-fix systems. Even auto npm install and pip install are… dangerous… as we have seen with litellm and axios…
TUI quit orphaning everything → proper signal handling
The original TUI had one keybinding: q to quit. Pressing it called app.exit(), which tore down the Textual dashboard but didn’t stop the orchestrator thread or its child processes. The run stayed running with no cleanup, and the underlying claude/codex subprocess might still be alive somewhere.
Now it’s: first ctrl-c pauses at the next checkpoint and sends SIGTERM to children. Second ctrl-c force-kills everything and releases the controller. TUI has p for pause, s for stop, q for quit. All of them clean up properly.
Durability as a first-class opinion
The v0.1 spec opens with this: “Unattended execution is not credible without durable state.” I had strong feelings about this going in. Every task state, every artifact, every provider invocation needs to survive anything.
Ralph-NG stores everything in SQLite under .git/ralph/:
.git/ralph/
state.db ← SQLite with WAL journaling
events.jsonl ← Append-only event stream
runs/<run_id>/
patches/<task_id>_attempt_N.patch ← Diff snapshots
prompts/<task_id>_attempt_N.md ← Prompts as sent
reviews/<task_id>_attempt_N.json ← Reviewer verdictsYou can pause, kill, resume. Close your laptop Thursday, open it Monday, ralph resume picks up exactly where it left off. The state store tracks controller PID, heartbeat, run status, and stop reason. Append-only for auditability — you can trace every decision both models made, every failure, every recovery attempt.
This is the least glamorous code in the whole project and the most important. The kind of boring stuff that means you can actually trust a multi-hour autonomous run.
The pipeline: from argument to PR
Here’s the full workflow when you put Crossfire and Ralph-NG together:
- Open Crossfire. Type your problem. Let Claude and Codex argue about it.
- Export the converged spec and implementation plan.
- Convert the plan to a
ralph-plan.yaml(there’s a companion skill for this). - Run
ralph start. Walk away. Go live your life. - Come back to a feature branch with atomic commits per task, verification passing, and a full audit trail of every decision both models made.
Debate the spec. Execute the plan. Review the PR.
The human is the architect, the decision maker, the one who says “ship it” or “go deeper.” Not the one typing semicolons.
The Helix Labs angle
I’ve been building AI infrastructure at Helix Labs alongside my security work at Offensive Guardian, and ralph-ng grew directly out of that effort. The question we keep coming back to at Helix: how do you make AI coding agents reliable enough to trust with real work?
Not demo work. Not “look what it built in 5 minutes on a conference stage.” Real work, where bugs cost money and bad architecture costs months.
The answer isn’t “use a smarter model.” Models will keep getting better. Self-review will get less terrible. But the gap between “model reviews itself” and “independent model reviews the work” isn’t closing. It holds for the same reason code review doesn’t go away when your developers get more senior. Fresh eyes catch things. Different training distributions surface different blind spots. That’s just how it works.
Ralph-NG is the execution layer for that thesis. Crossfire is the planning layer. Together they form a pipeline where every phase has adversarial tension, human oversight at the boundaries, and durable state that doesn’t evaporate when something goes wrong. That’s what we think trustworthy autonomous development looks like.
Not fire-and-forget. Launch, monitor, review.
Current status
Ralph-NG is in alpha. I’ve been running it on real projects (including parts of itself, which is a recursive nightmare I try not to think too hard about) and the results are genuinely better than I expected. Which makes me suspicious, because nothing I build works this well on the first serious iteration.
The evolution so far: v0.1 MVP (single-model loop with durable state), then the codex-reviewer-integration PR that added adversarial cross-model review, then reliability hardening driven by the maiden-voyage failure data, then a streaming pipeline overhaul, then operator visibility improvements. Nine commits on main, each one fixing something the previous version got wrong.
Open source release is here. The tests are real. The state machine is real. The system runs overnight without eating itself.
A few things I’m still chewing on:
- Brownfield support. Ralph-NG works well with plans that build new things. Making it work on existing codebases where “the plan” is “make this less terrible” is a different beast entirely. I’m actively researching this and it’s harder than it looks.
- Challenge round quality. The executor-reviewer negotiation works, but sometimes they converge too fast on style disagreements instead of arguing about substance. Getting the prompts right for productive disagreement (not just disagreement for its own sake) is an ongoing tuning exercise.
- The model election protocol. The design doc describes a system where both models self-assess their suitability for executor vs reviewer roles based on the problem. I haven’t built this yet — roles are configured, not negotiated. I figured that this was likely a bit too gimmicky and that the operator will want to keep that control.
If you wanna follow the progress, ralph-ng is at github.com/jfmaes/ralph-ng. And if you’ve been doing the “ask Claude, review it yourself, hope it’s fine” loop… I’ve been there. There’s a better way.
Your agent shouldn’t grade its own homework. Get it a study buddy with a different set of biases.