March 18, 2026
Crossfire: When One LLM Isn't Enough
I built a web app that makes Claude and Codex argue with each other before writing a single line of code. The specs are better. The code is better. Here's how.

The copy-paste workflow from hell
If you’re paying for both Claude and Codex subscriptions like I am, you’ve probably noticed the same thing: neither of them can write a good spec in one shot.
They’re impressive, don’t get me wrong. But “impressive first draft” and “ready to build from” are different planets. Every time I ask Claude to spec out a project, Codex finds real problems with it. Every time Codex produces a plan, Claude tears holes in the security model. And if you don’t push back on either of them, they’ll enthusiastically agree with their own flawed reasoning until you end up building something that falls apart at the first edge case.
So I developed a workflow. Ask Claude to design something. Copy the output. Paste it into Codex with “find every problem with this.” Copy those critiques. Paste them back into Claude. Back and forth across two browser tabs until they converge on something actually buildable.
I was doing this three, four times a week. Like some kind of AI switchboard operator.
And then I noticed something: the specs coming out of this manual adversarial process were significantly better than what either model produced alone. Not 10% better. The kind of better where the implementation phase just works. Minimal drift, minimal “oh wait, we never thought about X.” The human just steers and approves instead of constantly firefighting.
So naturally, I automated it.
Why I care about specs more than code
Hot take: the spec is the bottleneck, not the code. Once you have a good implementation plan, one that’s been stress-tested, that accounts for edge cases, that has concrete file paths and TDD task ordering, the actual coding is almost mechanical. Both Claude and Codex are excellent at turning well-defined plans into working code.
The problem is getting to that well-defined plan. LLMs are people-pleasers by default. Ask one model to spec something and it gives you something coherent and plausible. Looks great on first read. But “coherent and plausible” hides a lot of sins: unstated assumptions, architectural decisions that don’t survive reality, missing failure modes, scope that quietly ballooned because the model said yes to everything you implied.
The adversarial approach fixes this. When a second model reviews the first model’s work with the explicit instruction to find problems, it finds problems. Real ones. And when the first model has to defend its choices against specific critiques, the surviving design is dramatically more robust.
The question was: can I turn this into software instead of a copy-paste ritual?
Why this was harder than it should be
The obvious architecture would be an agentic SDK. Something like the Claude Agent SDK or OpenAI’s Agents API. Model A generates, pipe to Model B, collect response, pipe back. Clean, simple, streaming.
Except: Claude’s Terms of Service don’t allow you to use another harness to drive it programmatically. You can use the Claude CLI, but you can’t wrap it in a custom agent framework that treats it as a tool. And the Claude CLI doesn’t support streaming. You fire a prompt, wait in silence, and eventually get the full response. For complex prompts, that silence can last over a minute. Sometimes two.
Codex has its own personality. The codex exec command outputs newline-delimited JSON events, which is great for parsing but means a completely different transport layer than Claude.
So the architecture couldn’t be “just use an SDK.” It had to be CLI-based for both models, async, capable of parallel execution, and structured enough to extract useful data from whatever the models decided to return.
How hard could it be?
Narrator: It was hard.
The sycophancy problem (or: when AI is too polite to be useful)
The first version worked. Both models talked. Summaries appeared. Checkpoints fired.
And the output was nearly useless.
The problem was not the transport layer or the state machine or the UI. The problem was that Claude and GPT were being polite to each other. Turn after turn, they’d acknowledge the other’s points, restate them with a slight flourish, and declare consensus. Four exchanges of increasingly enthusiastic agreement, then a checkpoint that read like a press release: “Both models agree that the approach is sound and recommend proceeding.”
Thanks guys. Very helpful.
This is the sycophancy problem, and it’s well-documented. The AI Safety via Debate research (Irving et al.) showed that debate between models can surface truth, but only when the incentive structure rewards genuine disagreement. A 2025 paper called “Peacemaker or Troublemaker” found the worst outcomes happen when all agents are highly sycophantic. They converge on the first plausible answer instead of stress-testing it.
Alec Nielsen’s adversarial-review project made this concrete with code review: a single model caught 53% of bugs, but two models in structured adversarial debate caught 80%, and 100% of the hard system-level bugs. The difference wasn’t that the second model was smarter. It was that someone told it to find what the first model missed.
So the real design challenge was never “how do I get two models to talk.” It was “how do I get them to argue productively.”
Making the models fight (constructively)
The research pointed to four techniques that actually work. I combined all of them.
Third-person personas with professional stakes. Generic instructions like “be critical” produce generic results. But assigning a third-person persona like “You are Dr. Rivera, a principal engineer whose reputation depends on finding flaws” boosts independent reasoning by up to 63.8% compared to second-person instructions. GPT plays Dr. Chen, a systems architect who ships things that work. Claude plays Dr. Rivera, a security engineer who considers it a professional failure when a flaw ships because she was too polite to flag it.
Anti-sycophancy protocol. Every prompt includes explicit rules: agreement must be earned through evidence. Vague acknowledgments like “you raise a good point” are prohibited. Models are penalized for agreeing with flawed reasoning, not for disagreeing.
Phase-aware turn instructions. The debate isn’t identical turns on repeat. Turn 1 is independent analysis. Identify three concerns before stating any strengths. Turns 2-3 are cross-critique. Challenge at least two specific points before stating agreements. Late turns are defense and resolution. No new topics, just defend or concede every open challenge.
Disagreements fuel the loop, not stop it. This one cost me a wrong implementation before it clicked. The first version stopped the debate when the models disagreed. That’s backwards. Disagreement means they found something worth arguing about. Stopping on disagreement is like stopping a code review the moment someone leaves a comment. The debate now runs until both models have zero remaining disagreements (consensus), or until a 14-turn safety cap kicks in.
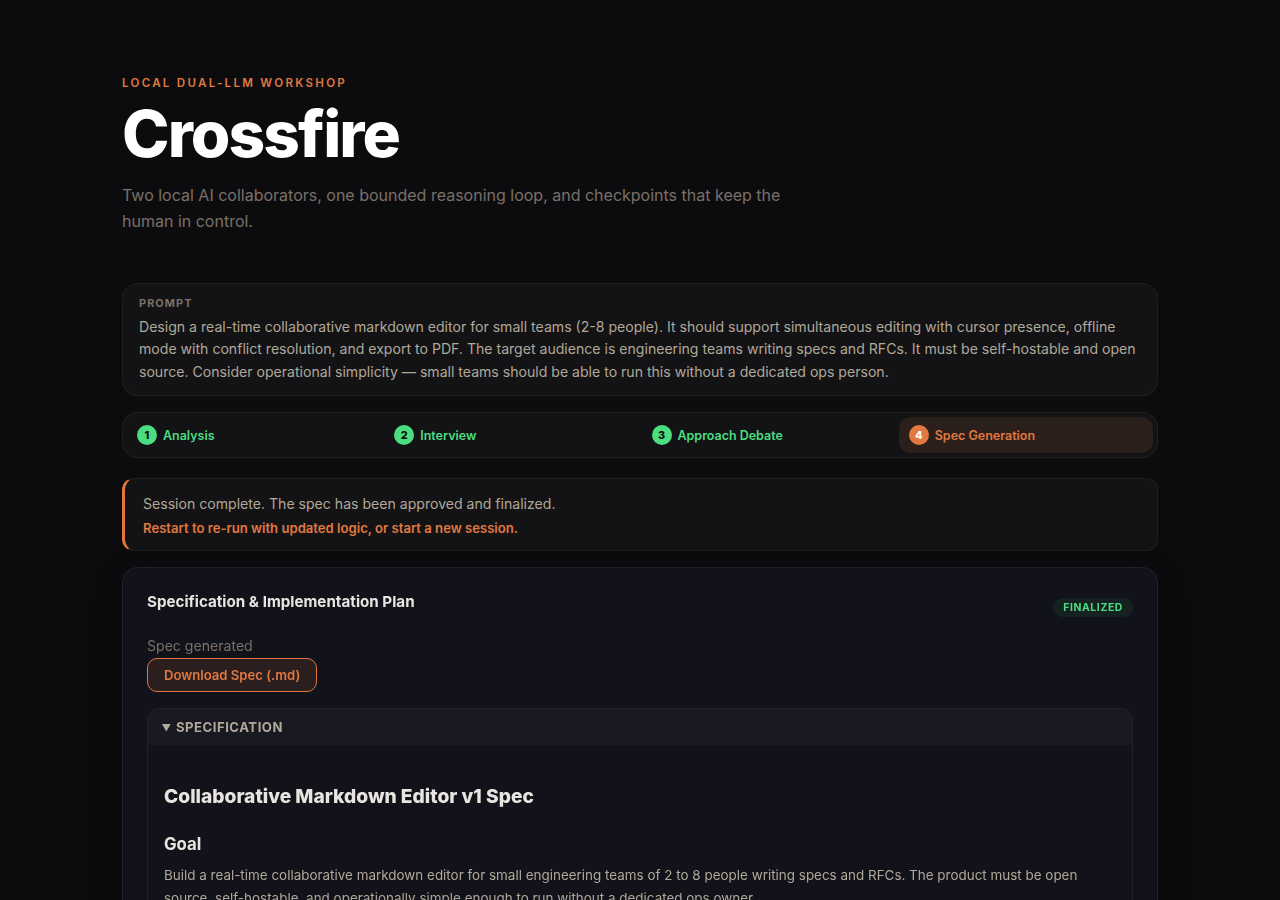
Crossfire: a four-phase spec workshop
Crossfire is a local web app that orchestrates everything. Instead of a single debate round, it runs four phases, the same structure a good human-led spec workshop would follow:
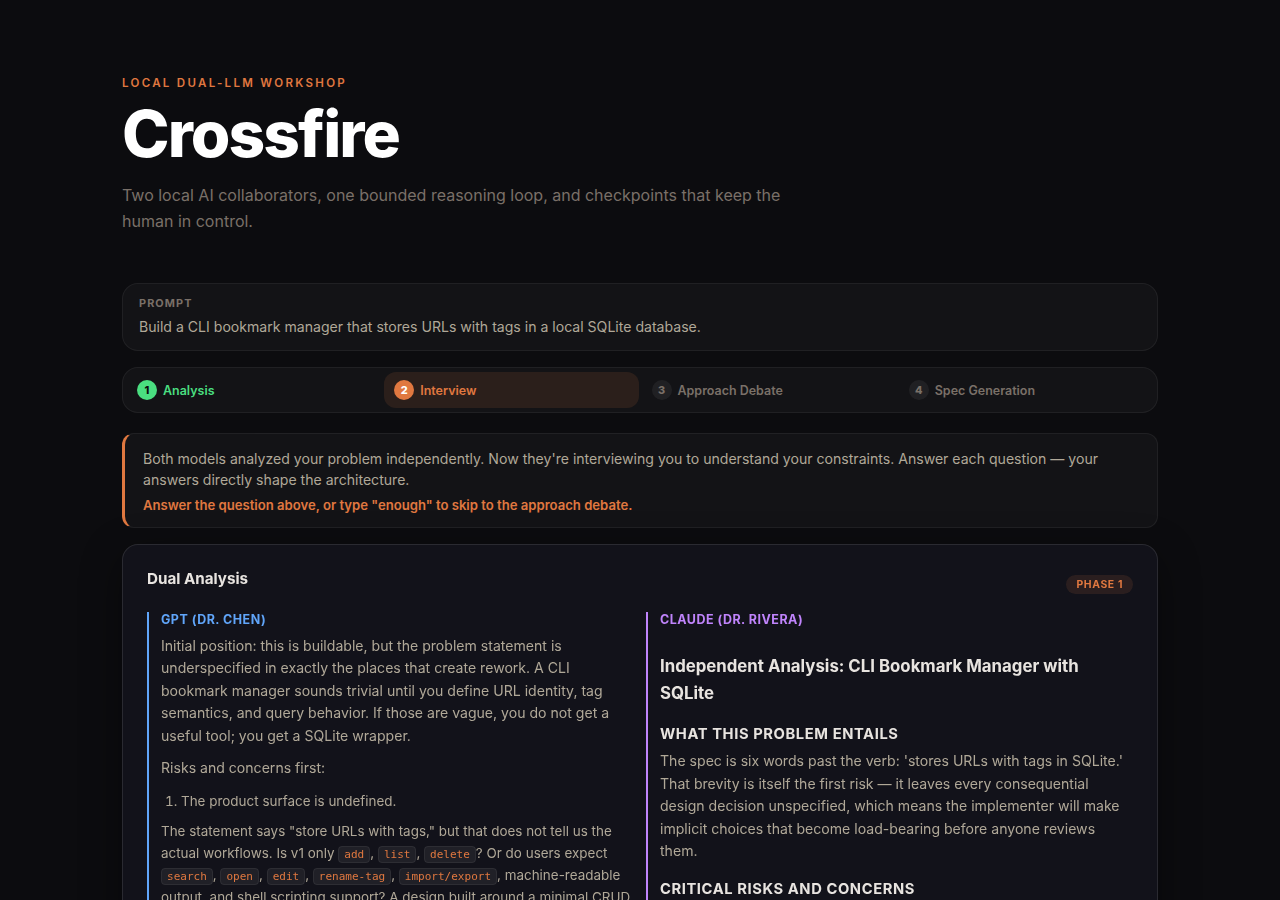
| Phase | What happens | Who |
|---|---|---|
| Analysis | Both models independently analyze the problem, then debate interview questions until they agree | GPT + Claude |
| Interview | Agreed questions presented one at a time, human answers instantly recorded | Human |
| Approach Debate | Consensus-driven adversarial debate on architecture (up to 14 turns) | GPT + Claude |
| Spec Generation | GPT drafts, Claude reviews, human approves or requests revisions | All three |
The key design insight: the debate starts early. The models argue about what to ask the human before the human answers anything. The human only sees questions after both models have debated and agreed on them.
Analysis: independent thinking, then a fight
Both models receive the problem statement simultaneously and work in parallel. No shared context, no peeking. This prevents the second model from anchoring on the first model’s framing.
I tested with “design a real-time collaborative markdown editor for small teams.” GPT (6,720 chars) decomposed it as a distributed systems problem, focusing on the tension between real-time collaboration, offline mode, and operational simplicity. Claude (14,526 chars) went deep on CRDTs vs OT as the single most consequential architectural choice and flagged that “offline mode” can mean at least three different things. A distinction GPT missed entirely.
Then, before the human sees anything, both models critique each other’s proposed questions. GPT argued product invariants should come first. Claude countered that operational constraints should come first because, and I’m quoting the actual output here, “if the answer is ‘single binary with embedded storage,’ it eliminates entire classes of sync architecture.” Both were right. A single model would have just picked one ordering.
Interview: the human enters the loop
Once the models agree on questions, the session auto-advances to the interview phase. No checkpoint, no waiting. The first question appears immediately alongside the dual analysis results for context.
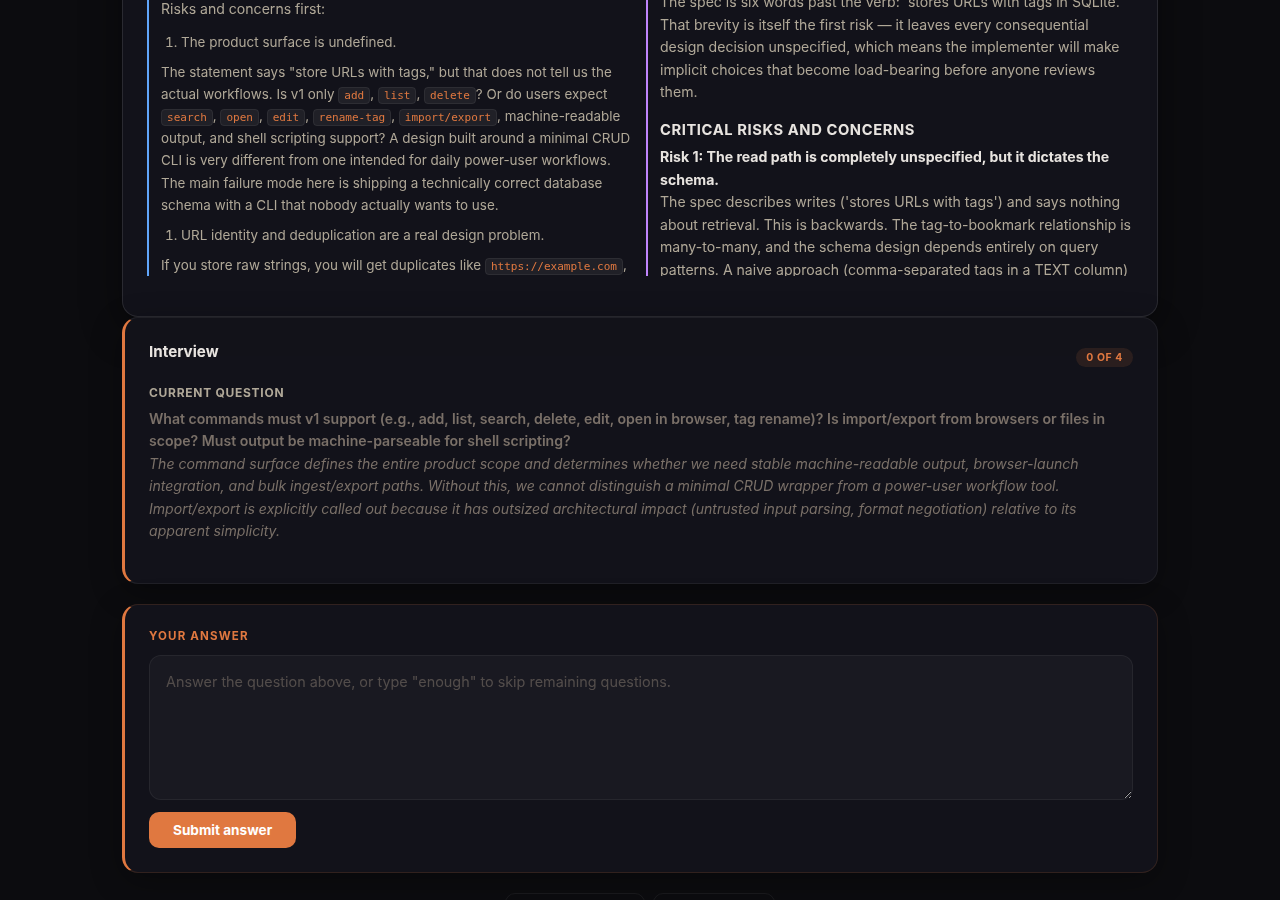
Answers are recorded instantly. No per-question LLM evaluation. In the original design, every answer triggered both models to evaluate it in parallel (~30-60s each). We removed this because the approach debate already sees all answers, giving the models better context anyway. The result: you can answer all questions in rapid succession instead of waiting minutes between each one.
You can type “enough” at any point to skip remaining questions. Sometimes three good answers are worth more than five mediocre ones.
Approach debate: arguing until they actually agree
With the problem statement plus the human’s actual answers, the models run a consensus-driven debate. Not a fixed number of turns. They argue until both have zero remaining disagreements, or until the 14-turn safety cap kicks in.
My test produced a 7,541-character converged approach with specific architectural decisions: structured CRDT model with deterministic CommonMark serialization rules for every construct, checkpoint-based history as core architecture (“history is mandatory architecture, not a later safety net”), SQLite WAL for single-node persistence, and explicit concessions: “I accept most of the peer’s risk analysis… but three corrections are necessary to make the design honest and buildable.”
That last part is what makes this work. The model explicitly states what it’s conceding and what it’s not. No silent agreement, no rubber-stamping.
Spec generation: two documents, draft, review, revise
This phase produces two separate artifacts: a specification and an implementation plan. GPT drafts both, Claude reviews and refines. If you don’t like something, type your feedback and the system re-runs generation with the previous output plus your notes as context. Only “approve” finalizes.
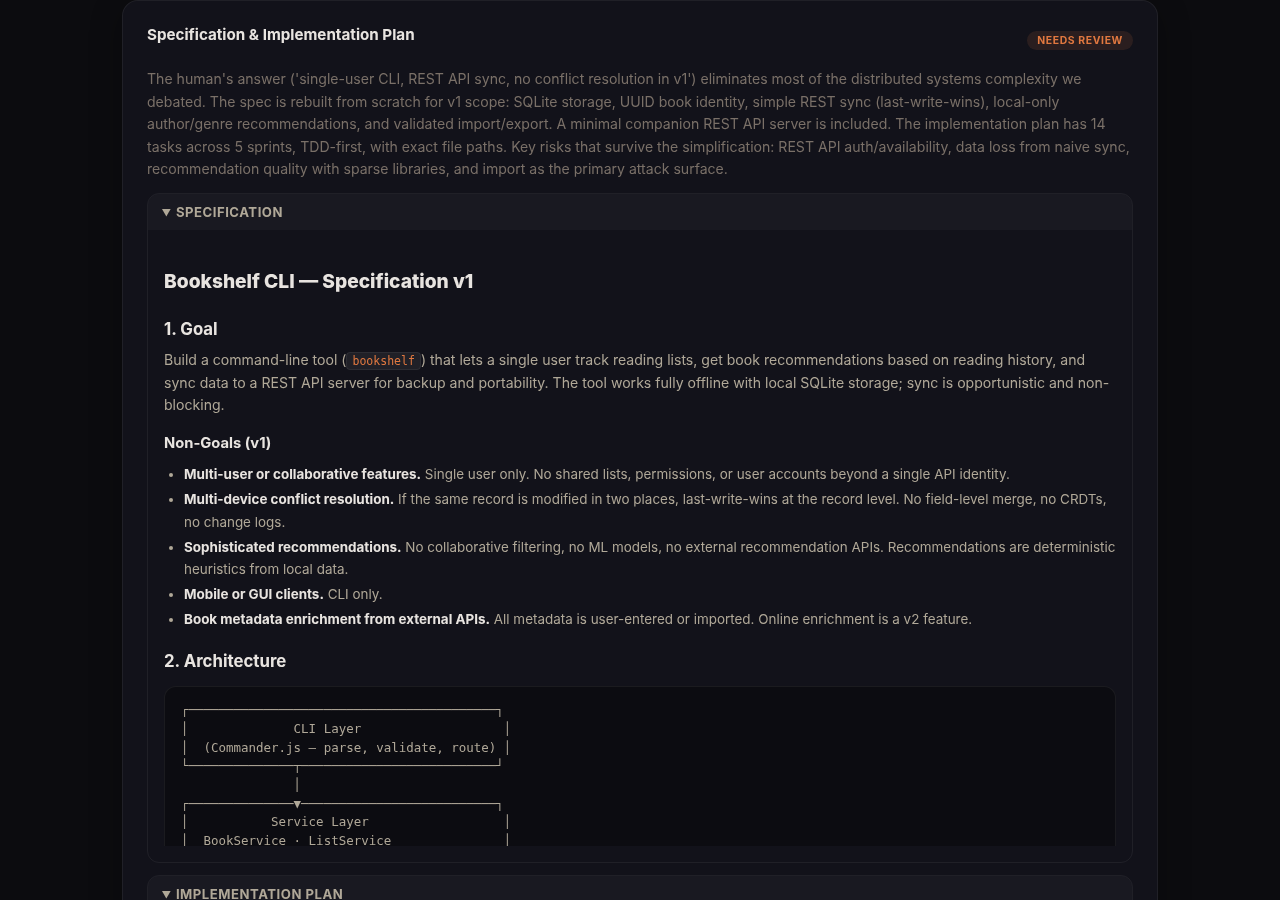
The specification covers goal, architecture, tech stack, design decisions, acceptance criteria, and risks. The implementation plan is the ordered task list: what to test first, what files to create, complexity estimates (S/M/L), dependencies, and sprint groupings.
My test produced 19,073 characters across both documents after one revision round. Once approved, both are written as .md files to the artifacts directory and downloadable from the UI. You can hand the implementation plan directly to Claude or Codex and start coding. That’s the whole point.
That’s not a rough idea. That’s a “sit down and start writing tests” deliverable.
The bugs that only real LLMs could find
Unit tests caught the logic bugs. But several critical issues only surfaced during the first real E2E test with live models.
The adapters were overwriting phase prompts. The Claude and Codex adapters always wrapped input in their standard debate prompt, silently replacing the carefully crafted phase-specific prompts with generic “you are Dr. Chen” instructions. Every phase looked like a debate turn. The fix was a one-line check, but finding it required running the full system and noticing the analysis output had debate formatting.
Claude’s JSON envelope. The Claude CLI wraps output in {"type":"result","result":"..."}. The system was storing the entire envelope instead of the inner content. Claude also wraps JSON in markdown code fences (```json...```), which broke the parser. Two layers of wrapping to strip.
30-second timeout. Claude’s analysis took 88 seconds. The system silently returned “Analysis unavailable” because the process was killed. I only noticed because GPT had a thorough 6,720-char analysis next to a blank card for Claude. It’s now 5 minutes.
The black box problem. The approach debate can take 3+ minutes of consecutive LLM calls. The UI showed “Reasoning…” and nothing else. Was it working? Stuck? Crashed? No way to tell. I added an SSE progress feed so the daemon streams real-time events ([GPT] Turn 3 done in 32.7s, 1 disagreements) and the frontend shows a live log. No more guessing.
Does it actually produce better specs?
Here’s the comparison from my real test with the collaborative markdown editor prompt:
| Approach | Spec length | Questions | Non-goals | TDD tasks | File paths |
|---|---|---|---|---|---|
| Single-shot Claude | ~4,000 chars | 0 | 2 vague | 5 generic | 0 |
| Single-shot GPT | ~3,500 chars | 0 | 1 | 4 generic | 0 |
| Crossfire | ~19,000 chars | 5 debated | 6 explicit | 15 specific | 45+ |
The single-shot specs were fine starting points. But they both made assumptions the human never validated, missed operational constraints, and produced task lists too vague to code from.
Crossfire’s spec was buildable. Deterministic serialization rules for every markdown construct. An 8-step reconnection protocol. Acceptance criteria. Risk assessment. And because the human answered targeted questions, the spec didn’t waste pages on features that were explicitly out of scope.
Total wall-clock time varies depending on prompt complexity. Anywhere from 10 to 25 minutes for the full four-phase flow, plus a couple minutes of human input. For a 19,000-character spec you can implement from, that’s a trade worth making. But let’s talk about where that time goes.
How it’s built
TypeScript monorepo. Four packages:
packages/
core/ - Zod schemas, phase state machine
adapters/ - Claude CLI + Codex CLI adapters, phase prompts
storage/ - SQLite (sessions, interview questions, phase results)
apps/
daemon/ - Fastify server, phase orchestrator, session service
web/ - React frontend with phase-aware UIThe phase orchestrator runs Promise.all for parallel phases (analysis) and delegates to the consensus-driven debate engine for approach debates. The daemon owns all state, the browser is just a view. SQLite stores everything including the full original prompt (not the 80-char truncated title. That was a fun bug).
The UI uses hash-based routing so back/forward work and you can bookmark sessions. A session list on the landing page shows all past sessions with their current phase and status. Click to resume, restart to re-run with updated logic, or delete to clean up. Each phase shows a guidance banner explaining what just happened and what to do next, because “Current understanding” and “Recommended direction” turned out to be meaningless labels that confused every tester.
On finalize, the daemon writes {sessionId}-spec.md and {sessionId}-plan.md to the artifacts directory. The UI shows download buttons. The whole point of this tool is to produce artifacts you can hand to a coding agent. If the output isn’t a file you can use, it’s a demo, not a tool.
The elephant in the room: latency
Let’s be honest about what a real session looks like. Here are actual timings from a smoke test with a simple prompt (“build a CLI bookmark manager with SQLite”):
| Phase | Claude | Codex (GPT) | Wall clock |
|---|---|---|---|
| Analysis (parallel) | 71s | 210s | ~3.5 min |
| Question debate (5 turns) | 47-72s/turn | 65-160s/turn | ~8 min |
| Interview (3 answers) | n/a | n/a | ~30s (instant, no LLM) |
| Approach debate (8 turns) | 50-88s/turn | 0.1-0.2s/turn | ~5 min |
| Spec generation | 258s | 5+ min cold | ~5 min |
Total: ~22 minutes. For a simple prompt. Complex prompts with grounding context (40k+ chars of source files) take longer.
A few things jump out from the data.
Codex is 2-3x slower than Claude on cold calls. Every fresh codex exec invocation takes 1-3 minutes, while Claude completes the same work in 50-90 seconds. This is consistent across every phase.
Session reuse is transformative, but only within debates. Both CLIs support conversation continuation: Claude via --resume <session_id>, Codex via exec resume <thread_id>. We capture the session/thread ID from the first turn and resume on subsequent turns within the same conversational context. The approach debate shows the impact most dramatically: Codex turns drop from 160s to 0.1s. A 1000x improvement. The model’s conversation cache handles the heavy lifting. Claude benefits too, averaging 50-80s per turn with --resume versus re-sending the full context each time.
Cross-phase resume doesn’t work for Codex. Claude handles conversation continuation gracefully across completely different prompt structures (debate into spec generation). Codex does not. Resuming a debate thread for spec generation returns empty content. So Codex gets session reuse within multi-turn debates but starts fresh for each distinct phase. This is the single biggest remaining performance gap.
Interview answers are now instant. We removed the original per-question LLM evaluation that called both models after every answer (~30-60s per question). Answers are recorded immediately and the models see everything together during the approach debate. This saves 2-5 minutes on a typical 3-5 question interview.
Why not use the APIs directly?
The obvious question: if CLI process spawning is the bottleneck, why not call the Anthropic API and OpenAI API directly? Persistent connections, streaming, no process overhead. It would be dramatically faster.
The answer is philosophical, not technical. The whole point of Crossfire is to leverage existing CLI subscriptions. If you’re already paying for Claude Code and Codex, you’re paying for unlimited usage through those CLIs. Switching to direct API calls means paying per-token on top of your existing subscriptions, and for a tool that makes 10-20 LLM calls per session with large prompts, the costs add up fast.
The adapter interface (ProviderAdapter.sendTurn() is an async generator that yields events) is designed to support both approaches. If someone wants to build API-based adapters for lower latency, the architecture supports it cleanly. But the default deployment uses the CLIs because that’s what most users are already paying for.
Other speed improvements
Beyond session reuse, we made several changes that compound:
- Auto-advance from analysis to interview. The old flow stopped at a checkpoint between analysis and interview, requiring the user to click “Continue” (which didn’t even work, the form silently rejected empty input). Now analysis flows directly into the first interview question.
- Relaxed question counts. The analysis prompt asked for “3-5 critical questions,” which models interpreted as “always produce exactly 5.” Changed to “up to 5, fewer is better.” Models now ask 2-4 questions instead of always 5.
- Per-phase thread tracking for Codex. Codex can’t resume across different phases, but it can resume within the same phase (e.g., question debate turn 1 to turn 3 to turn 5). We track threads per phase so Codex gets the speed benefit wherever possible.
What’s next
The adversarial pattern is general. The same structure applies beyond specs: one model proposes, the other critiques, they converge, the human steers.
- Code reviews. GPT reviews Claude’s implementation, Claude reviews GPT’s, they debate disagreements.
- Architecture decision records. Debate trade-offs before committing.
- Threat modeling. Adversarial by nature, perfect for dual-LLM analysis.
- Next-generation RALPH loops. Recursive adversarial planning with human checkpoints.
The whole thing runs locally. Two CLI subscriptions you’re already paying for, one SQLite file, two terminal tabs. No cloud, no data leaving your machine.
If you’ve been doing the same manual copy-paste adversarial dance between Claude and Codex, maybe it’s time to let them argue directly.
I suspect this won’t stay a spec-only tool for long. The daemon already does the hard part: orchestrating two frontier models, managing turn state, and making them actually disagree. That same engine slots into RALPH loops, code reviews, threat models, anything where two adversarial models produce better output than one polite one. The spec workshop was just the first use case.
Crossfire is available at github.com/jfmaes/crossfire. PRs welcome.